| ** | Latin American Journal of Clinical Sciences and Medical Technology is an open access magazine. To read all published articles and materials you just need to register Registration is free of charge. Register now If you already have registered please Log In | ** |




 0000-0003-1540-8095)a; Jaime Altamiranob; Ximena Mimicab; Isabel Saffieb; Gabriela Villavicenciob; Inti Paredesb.
0000-0003-1540-8095)a; Jaime Altamiranob; Ximena Mimicab; Isabel Saffieb; Gabriela Villavicenciob; Inti Paredesb.aHospital Sant Joan de Deu; bInstituto Oncológico Fundación Arturo López Pérez.
Corresponding Author: , . Telephone number: ; e-mail: cristobal@speaknosis.com

Lat Am J Clin Sci Med Technol. 2026 Mar;8:25-37.
Received: January 7th, 2026.
Accepted: February 27th, 2026.
Published: March 10th, 2026.
Views: 754
Downloads: 10

Introduction. Clinical documentation is a major administrative challenge in healthcare, particularly in oncological surgery, where precision is essential. Objective. This study assessed the impact of Speaknosis, an AI-powered medical scribe, on documentation time (AI draft generation time), record quality, physician satisfaction, and patient experience at the oncology unit of Instituto Oncológico Fundación Arturo López Pérez (FALP). Materials and Methods. A prospective observational study was carried out during the study period (March 11th to April 28th, 2025) in FALP’s outpatient clinics. Speaknosis was used to generate clinical notes from physician-patient encounters. AI-generated notes were compared to final physician-reviewed versions using semantic similarity metrics (BERTScore and Clinical BERTScore). Physician satisfaction and patient perceptions were evaluated through structured questionnaires. Results. A total of 123 clinical note pairs were analyzed. Semantic similarity was high (BERTScore: 0.889; Clinical BERTScore: 0.917), indicating accurate capture of medical content. Physicians reported high satisfaction with the tool (mean score: 4.37/5). From the patient perspective, 93.6% felt very comfortable during consultations using Speaknosis, and 81.8% perceived improved communication with their doctor. Discussion. Speaknosis generated clinically coherent draft notes within seconds and achieved high semantic similarity with physician-finalized documentation, while maintaining high physician satisfaction and a positive patient experience. Conclusions. Speaknosis generated clinically coherent draft notes within seconds and achieved high semantic similarity with physician-finalized documentation, while maintaining high physician satisfaction and a positive patient experience.
Introducción. La documentación clínica representa un importante desafío administrativo en la atención médica, especialmente en la cirugía oncológica, donde la precisión es fundamental. Objetivo. Este estudio evaluó el alcance de Speaknosis, un escriba médico impulsado por inteligencia artificial (IA), en el tiempo de documentación (tiempo de generación del borrador por la IA), la calidad de los registros, la satisfacción del médico y la experiencia del paciente en la unidad de oncología del Instituto Oncológico Fundación Arturo López Pérez (FALP). Material y métodos. Se llevó a cabo un estudio observacional prospectivo durante el período de estudio (del 11 de marzo al 28 de abril de 2025) en las clínicas ambulatorias de FALP. Se utilizó Speaknosis para generar notas clínicas a partir de los encuentros entre médico y paciente. Las notas generadas por la IA se compararon con las versiones finales revisadas por los médicos utilizando métricas de similitud semántica (BERTScore y Clinical BERTScore). La satisfacción de los médicos y las percepciones de los pacientes se evaluaron mediante cuestionarios estructurados. Resultados. Se analizó un total de 123 pares de notas clínicas. La similitud semántica fue alta (BERTScore: 0.889; Clinical BERTScore: 0.917), lo que indica una captura precisa del contenido médico. Los médicos informaron alta satisfacción con la herramienta (puntuación media: 4.37/5). Desde la perspectiva del paciente, el 93.6% se sintió muy cómodo durante las consultas utilizando Speaknosis, y el 81.8% percibió mejor comunicación con su médico. Discusión. Speaknosis generó borradores de notas clínicamente coherentes en cuestión de segundos y logró alta similitud semántica con la documentación finalizada por el médico, lo cual al mismo tiempo mantuvo alta satisfacción médica y una experiencia positiva para el paciente. Conclusiones. Speaknosis generó borradores de notas clínicamente coherentes en cuestión de segundos y logró alta similitud semántica con la documentación finalizada por el médico, lo cual al mismo tiempo mantuvo alta satisfacción médica y una experiencia positiva para el paciente.
Clinical documentation remains one of the most significant administrative burdens faced by modern healthcare providers. This challenge is particularly pronounced in high-stakes environments, such as oncological surgery, where clinicians must navigate and document complex diagnostic and therapeutic information.
Surgeons and oncologists are responsible for accurately documenting detailed patient histories, intricate surgical procedures, treatment decisions, and long-term follow-up plans. Such documentation is essential for ensuring continuity of care, facilitating interdisciplinary collaboration, supporting medicolegal accountability, and enabling future clinical research.
However, the time and cognitive resources required for this level of detail often detract from direct patient care and have been identified as major contributors to physician burnout.1,2 It has been reported that physicians may spend up to 50% of their working hours on administrative tasks, often double the time they devote to direct clinical care, effectively shifting their role from healthcare providers to mere documenters of medical information.
The introduction of Electronic Health Records (EHRs) aimed to enhance the accessibility, standardization, and quality of clinical documentation. Paradoxically, however, EHRs have often increased the documentation burden due to suboptimal user interfaces and inflexible workflows1, contributing to clinician dissatisfaction and workflow inefficiency.
In response, the Office of the National Coordinator for Health Information Technology (ONC) issued recommendations to improve EHR usability and reduce this burden by aligning digital tools more closely with clinical needs.3 Nevertheless, the fundamental challenge of documenting large volumes of patient data remains. These challenges are magnified in oncological surgery.
Cancer care requires meticulous multidisciplinary documentation under high-pressure conditions. Accurate records are crucial for treatment planning, staging, and monitoring outcomes, as even minor documentation errors can have serious clinical consequences. Thus, tools that alleviate the documentation burden without compromising record quality are critical.
Emerging evidence indicates that AI-powered medical scribes may offer a solution. In addition to automating transcription, these technologies represent a potential paradigm shift in high-stakes clinical documentation.4,5 Early studies suggest that artificial intelligence (AI) scribes can significantly reduce documentation time while improving physician engagement and communication in patient care.6,7 In oncology, where decision-making is complex and communication is pivotal, these tools could be transformative in the future.
AI scribes integrate advanced technologies, including real-time speech recognition, natural language processing (NLP), and machine learning (ML), to transcribe clinical conversations and generate structured medical notes. Speech recognition algorithms accurately capture diverse accents and specialized medical vocabulary8, whereas NLP interprets context, distinguishes speakers, and extracts clinically relevant information.8 ML-driven systems continuously improve through iterative learning using large datasets.9
Many AI scribes operate ambiently without requiring direct clinician input during encounters. This allows physicians to maintain full focus on patient care while the system unobtrusively records, processes, and generates standardized notes for EHR integration.10 The generated notes commonly follow the Subjective, Objective, Assessment, Plan (SOAP) format, ensuring compatibility with institutional documentation requirements.10
In an oncological outpatient setting, does the use of an AI-powered medical scribe (https://Speaknosis.com) improve documentation-related outcomes—specifically AI draft generation time and note quality—while maintaining high physician satisfaction and a positive patient-centered experience?
We hypothesized that:
- The AI scribe would generate draft clinical notes rapidly (seconds-level draft generation time);
- AI-generated drafts would show high semantic similarity with physician-finalized notes (high BERTScore/CBERTScore);
- Physicians would report high satisfaction with AI-assisted documentation; and
- Patients would report high comfort and perceived preservation or improvement of patient-centered communication during consultations.
We conducted a prospective observational study to evaluate the performance and usability of an AI-powered medical scribe in a real-world clinical setting.
The study was conducted at Instituto Oncológico Fundación Arturo López Pérez (FALP), a high-volume academic oncological surgery hospital, characterized by complex clinical cases and multidisciplinary treatment coordination.
Data were collected during the study period (March 11th to April 28th, 2025).
The participating clinicians used the AI scribe (Speaknosis) during routine outpatient consultations and assessed the resulting documentation for quality and completeness.
Participants and Sampling
We included consecutive outpatient consultations in which Speaknosis was used during the study period (convenience sampling based on the predefined study period).
Eligible participants were patients attending routine outpatient visits in the oncology unit who provided informed consent for audio recording and survey participation.
Although the clinic primarily serves adults, all ages were eligible; pediatric cases were not a target population and were included incidentally when they occurred within the routine clinical schedule. Therefore, the findings should not be generalized to pediatric populations.
For this study, the system was operated independently as a standalone web application (Speaknosis.com) rather than being integrated into the institution's EHR. Although integration is technically feasible, this separation was maintained for academic and methodological purposes.
Data Collection
Datasets were collected, comprising paired clinical reports from outpatient consultations.
During the study period, 110 patients completed the post-consultation survey.
For the semantic-quality analysis, 123 paired notes (AIResult vs. physician-edited medicalReport) were available and included.
Differences in sample size reflect the availability of paired documentation outputs and completeness of exported records for the semantic analysis. Each pair consisted of an AI-generated draft note (AIResult) and the corresponding final physician-edited version (Medical Report), which served as the reference. The associated metadata included:
- audioDuration.Duration of the audio-recorded consultation session.
- Report-generating time. Time taken by the AI system to generate the initial draft.
- satisfactionRate. Physician satisfaction score for each AIResult on a 5-point Likert scale.
For embedding-based semantic similarity analyses (BERTScore and CBERTScore), we applied minimal preprocessing to preserve contextual information: we removed extraneous whitespace while retaining punctuation, numerals, and casing.
Lowercasing and dictionary-based filtering were applied only to the clinical-term-focused component (BERTclinical) to standardize term matching against the curated clinical dictionary. This approach avoids altering the contextual cues used by transformer embeddings while keeping term matching consistent for the clinical-filtered component.
Quantitative Measures
- Interaction and Audio Duration. Number of unique AI interactions and duration of audio recordings per consultation.
- Semantic Similarity (BERTScore). The semantic relevance and response accuracy of AI-generated reports were assessed using the BERTScore metric, which is based on contextual embeddings. Calculations were performed using the BERT-score package and the BERT-base-uncased model.
- Clinical Relevance (CBERTScore). To better emphasize the preservation of clinically meaningful content, we defined a Clinical BERTScore (CBERTScore) as a composite metric combining
- The standard BERTScore computed on the full texts (BERTgeneral) and
- A “clinical-term-focused” BERTScore computed after filtering both AIResult and medicalReport to retain only terms present in a curated clinical dictionary (BERTclinical).
The clinical dictionary was curated from institutional oncology/outpatient documentation templates and commonly used medication/procedure lists at FALP and was reviewed by clinicians for relevance (approximately 250 terms, including diagnoses, medications, procedures, symptoms, and abbreviations).
The dictionary was used solely as a filter (not for model training). We then computed: CBERTScore = w × BERTclinical + (1 − w) × BERTgeneral, with w = 0.4. This weighting reflects an a priori balance between overall semantic alignment and clinical-term retention; future work will include sensitivity analyses across alternative weights to evaluate robustness of conclusions. We report both components (BERTgeneral and BERTclinical) and the composite CBERTScore for transparency.
Computational environment
Analyses were conducted in Python 3.11 using bert-score (0.3.13), transformers (4.55.2), torch (2.8.0), scipy (1.16.1), and pandas (2.3.1). BERTScore was computed with the bert-base-uncased model. To facilitate reproducibility, the analysis script and configuration are available upon request from the corresponding author.
Physician Satisfaction
Satisfaction with AI-assisted documentation was measured using a 5-point Likert scale survey administered immediately after each consultation.
At the end of the study, all physicians completed a structured, self-administered questionnaire to assess the usability, effectiveness, and user satisfaction with the Speaknosis AI-powered medical scribe in clinical practice.
The instrument comprised 13 items distributed across six key domains:
- Training and introduction to the system
- Impact on clinical workflow
- Precision and reliability of the documentation generated
- Usability and integration into daily practice
- Overall satisfaction
- Recommendations
Participants were instructed to answer all questions based on their recent experiences with the AI scribe. The response formats included five-point Likert scales (e.g., “Very satisfied” to “Very dissatisfied”), multiple-choice options, and frequency scales (e.g., “Rarely” to “Very frequent”).The questionnaire emphasized capturing both qualitative perceptions (clarity of explanation, perceived workflow improvements, and patient focus) and quantitative outcomes (time savings in documentation and the frequency of error correction).
Patient Satisfaction Questionnaire
A structured, self-administered questionnaire was designed to capture patient perceptions and experiences regarding the use of Speaknosis AI-powered medical scribe during clinical consultations.
The instrument comprised items evaluating various dimensions of the patient experience, including perceived clarity of the physician's introduction to the system, comfort during consultations, perceived impact on communication quality and efficiency, perceived physician attention, and data confidentiality.
Patients were asked to rate their experiences using Likert-scale items with options ranging from "Very clear" to "Not at all clear" for clarity; "Very Comfortable" to "Neutral" for comfort; and "Very Satisfied " to "Neutral" for overall satisfaction.
Additionally, the participants evaluated whether the system improved communication quality, allowed physicians to focus more on patient care, and enhanced consultation efficiency.
The perceptions of information confidentiality and willingness to recommend the system to others were also assessed. The survey was completed anonymously and independently, ensuring that the responses reflected genuine patient experiences with the system.
AI Documentation System
The AI-assisted documentation system used in this study was the Speaknosis version [3.1].
The software used in this study integrates large language models (LLMs) without requiring direct training of the model. Specifically, we utilized Gemini Flash 2.0 for report generation and Gemini Flash 1.5 for the transcript. This choice ensured that our data remained private, as Google Gemini guarantees that user data is not employed to train its models. This system uses NLP and ML algorithms to generate medical reports from audio recordings of physician-patient interactions.
Transcription editing was performed online in real time to assess the effectiveness of the Speaknosis web application in facilitating accurate and efficient medical documentation.
As the Speaknosis application transcribed each audio recording, a medical professional reviewed and edited the transcripts. This immediate editing step was a critical quality-control measure that enabled the study to systematically identify and record deviations from the original spoken content in AI-generated text.
Ethical Considerations
Ethical approval was obtained from the Institutional Review Boards of the participating hospital. This study adhered to the ethical principles of informed consent, confidentiality, and data privacy.
The participants were informed of the study's purpose, procedures, risks, and benefits. All collected data were kept confidential and secure.
Data protection and confidentiality in clinical studies of speech-to-text systems were kept for medical consultation. The collection and analysis of voice data in clinical research raise significant concerns regarding data privacy and confidentiality issues. In the context of this clinical study, which aimed to evaluate the usability of a speech-to-text system for medical consultations, data protection measures adhered to the stringent requirements of the General Data Protection Regulation (GDPR). The GDPR, a regulation adopted by the European Union (EU), mandates robust data protection measures for personal data collected within the EU. To ensure compliance with applicable data protection requirements (including GDPR where relevant), the study implemented the following measures.
- Obtaining informed consent. Participants were provided with clear and comprehensive information about the data collection process, ensuring that they are fully aware of their rights and the intended use of their voice data.
- Data minimization. Only the voice data necessary for the study's objectives were collected, minimizing the amount of personal data stored.
- Data security. Voice data is stored securely using encryption and access control mechanisms to prevent unauthorized access, disclosure, or modification.
- Voice data was retained for a limited period, adhering to the study objectives and regulatory requirements.
- Participant rights. Participants have the right to access, rectify, erase, or restrict the processing of their voice data.
Data Analysis
Continuous variables were summarized using mean (SD) or median (IQR), as appropriate. Normality was assessed using the Shapiro-Wilk test.
Since semantic similarity metrics were paired at the note level and showed non-normal distributions, we used the Wilcoxon signed-rank test as the primary paired comparison; paired t-tests were used only as sensitivity analyses when the Shapiro-Wilk test did not indicate departure from normality for the paired differences.
Associations between continuous variables were assessed using Spearman’s rank correlation (primary) and Pearson correlation (secondary) depending on distributional assumptions.
Statistical significance was set at p <0.05 (two-sided). All analyses were conducted in Python 3.11 using pandas, scipy, matplotlib, and bert-score.
Participant Characteristics
A total of 110 patients who underwent outpatient consultations involving the use of an AI-powered medical scribe between March 11th and April 28th, 2025, completed a post-consultation satisfaction survey.
The demographic characteristics of this cohort are detailed in Table 1.
| Table 1. Patient demographics and AI note analysis metrics | |
|---|---|
| Variable | |
| Total patients (N) | 110 |
| Sex, female (%) | 46.4 |
| Mean age (SD), years | 56.7 (13.7) |
| >60 years | 54 (49.1%) |
| 46-60 years | 28 (25.5%) |
| 31-45 years | 22 (20%) |
| 18-30 years | 5 (4.5%) |
| < 18 years | 1 (0.9%) |
| Physician satisfaction score (1-5), mean (SD) | 4.37 (0.81) |
| Audio duration (minutes), mean (SD) | 10.5 (8.34) |
| AI report generation time (seconds), mean (SD) | 17.73 (9.24) |
| BERTScore F1 (general), mean (SD) | 0.889 (0.14) |
| Clinical BERTScore (CBERTScore), mean (SD) | 0.917 (0.11) |
The sample exhibited a near-equal sex distribution, with 58 males (52.7%) and 51 females (46.4%). One participant (0.9%) declined to report their sex. The majority of the respondents were aged over 60 years (49.1%), with an additional 25.5% aged between 46 and 60 years.
Descriptive Analysis of AI-generated Notes
A total of 123 AI-generated clinical note pairs were included in the semantic-quality analysis. Each pair consisted of an AI-generated draft (AIResult) and the corresponding physician-edited version (medicalReport).
Note on unit of analysis, the patient survey sample (n=110) and the semantic-quality sample (n=123 paired notes) differ because paired note exports were available for additional AI-assisted consultations in which the post-consultation patient survey was not completed or could not be linked. Therefore, 13 additional note pairs were included in the semantic analysis. The key descriptive statistics are presented in Table 1.
The mean satisfaction rating assigned by physicians to the AIResult notes was 4.37 (SD: 0.81) on a 5-point scale.
The average consultation audio duration was 632.8 s (approximately 10 min and 42 s), ranging from 0 to 2520 s, and the AI system’s mean report generation time was 17.73 seconds (SD: 9.24 seconds).
Semantic analysis yielded a high average BERTScore F1 of 0.889 (SD: 0.14), indicating a strong overall alignment between AI-generated and physician-finalized notes. The Clinical BERTScore (CBERTScore), designed to emphasize the retention of medically relevant terms, had a slightly higher mean of 0.917 (SD: 0.11), reflecting a tighter distribution and enhanced semantic precision in domain-specific content (Graphic 1).
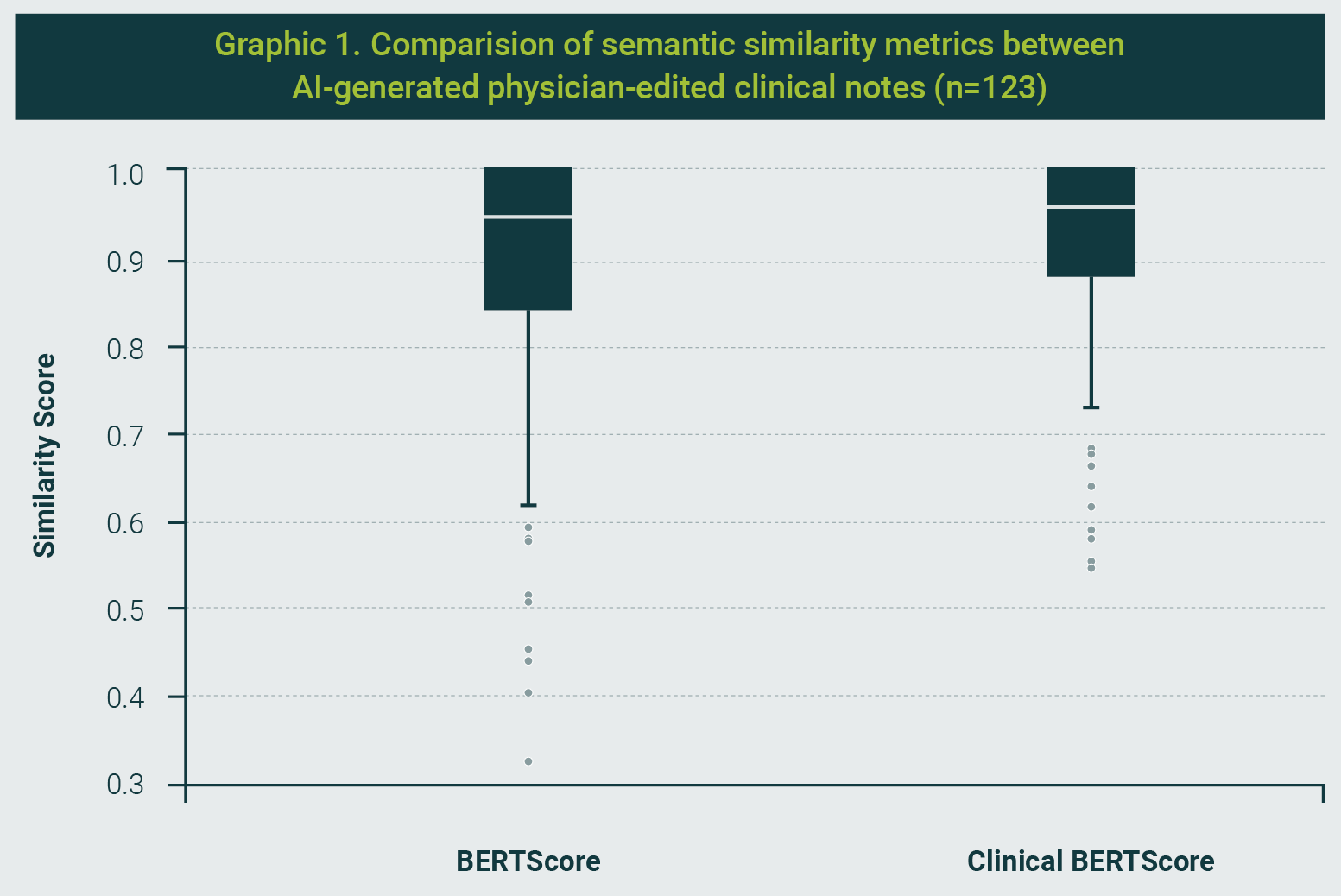
Interpretation of Similarity Metrics
BERTScore and CBERTScore range from 0 to 1, where values closer to 1 indicate greater semantic similarity between texts. Since no universal clinical cutoffs exist for “acceptable” similarity across note types, we interpreted results comparatively (AI vs. final notes within the same setting) and emphasized paired differences and their statistical uncertainty rather than fixed thresholds.
Statistical analysis demonstrated that while the CBERTScore tended to outperform the general BERTScore, the difference was not statistically significant.
The paired t-test revealed a t-statistic of -1.91 (p = 0.058), and the Wilcoxon signed-rank test yielded a W-statistic of 3807.0 (p = 0.145), both indicating similar semantic performance across both metrics. These findings underscore the system's effectiveness in generating semantically accurate and clinically coherent notes with minimal differences in general versus clinically focused similarity measures.
Correlation Analysis of Semantic and Satisfaction Metrics
To further investigate the relationship between semantic similarity and physician satisfaction, we analyzed the correlations between the BERTScore and Clinical BERTScore with physician satisfaction ratings (Graphic 2). The results indicated a weak negative correlation between BERTScore and satisfaction (Spearman: -0.169, p = 0.059; Pearson: -0.189, p = 0.035), suggesting that higher general semantic alignment between AI-generated and physician-edited notes did not necessarily translate into higher satisfaction.
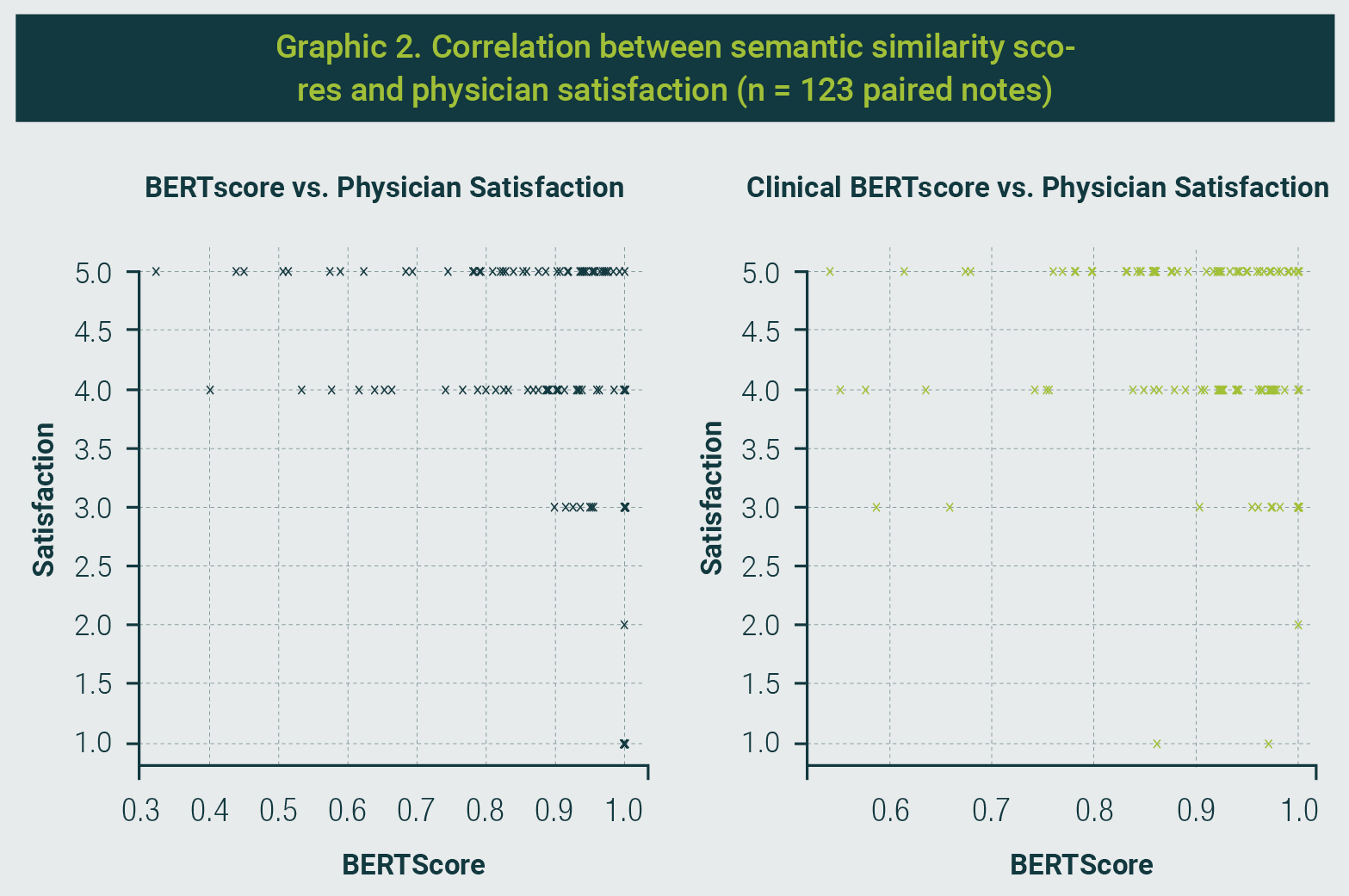
Conversely, the Clinical BERTScore, which emphasizes medical terminology retention, showed no meaningful correlation with satisfaction ratings (Spearman: -0.023, p = 0.799; Pearson: 0.011, p = 0.900). These findings highlight a potential disconnect between surface-level semantic similarity and subjective satisfaction, underscoring the need to consider both technical accuracy and clinical relevance when evaluating AI-generated documentation.
Patient-Reported Outcomes on AI Scribe Use
Patient satisfaction with the AI-powered scribe was evaluated using a structured survey that encompassed the key dimensions of the clinical experience.
The complete results are presented in Graphic 3. Overall, the responses indicated a highly favorable reception of the technology.
A large majority of patients (90.0%) rated the physician's explanation of the AI scribe as "very clear," with no reports of confusion or lack of clarity. Comfort during the consultation was similarly rated as "very comfortable" by 93.6% of respondents, indicating minimal intrusion by technology.
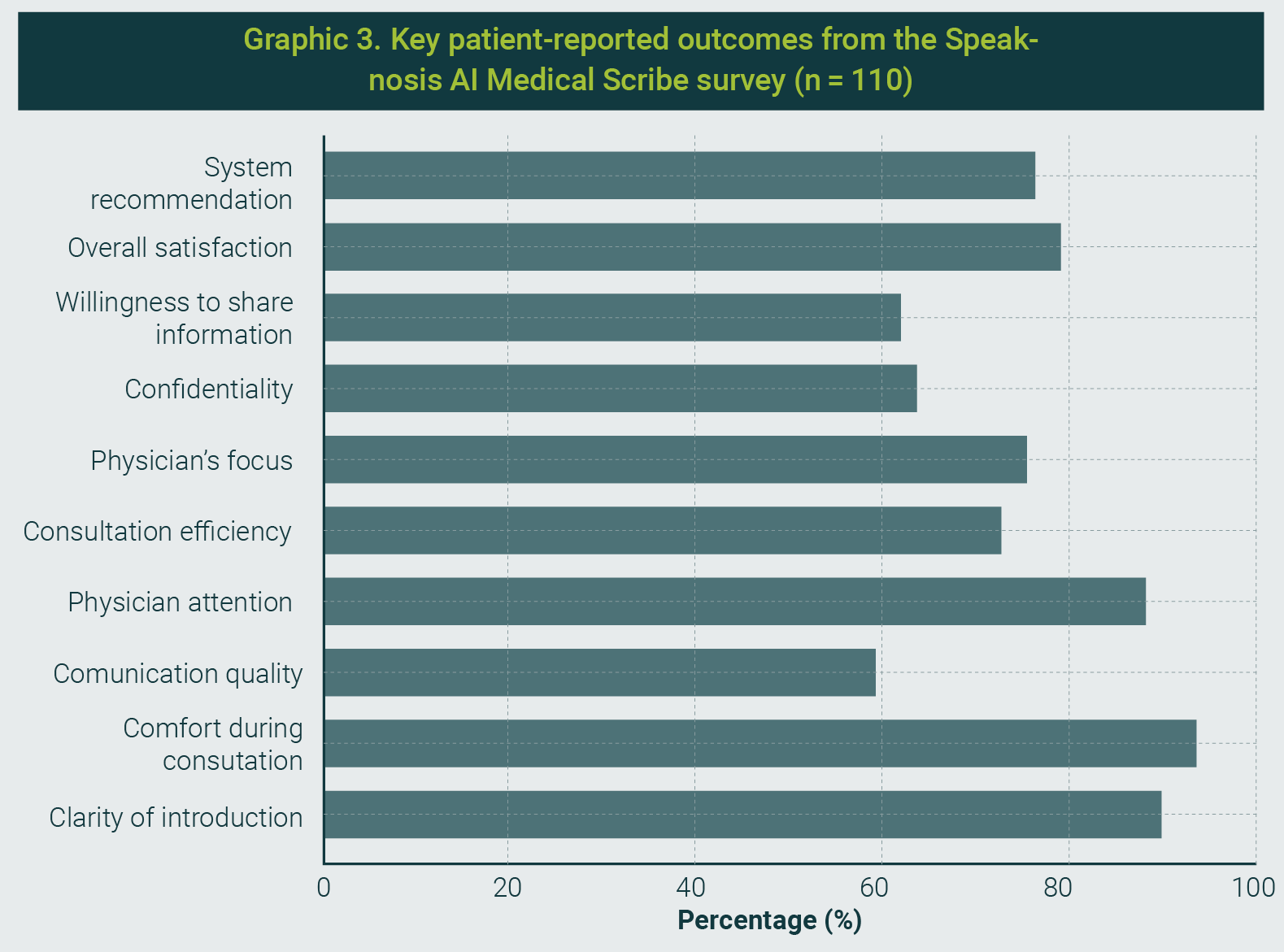
In terms of perceived communication quality, 81.8% reported that the AI scribe either "significantly improved" (59.1%) or "improved" (22.7%) the interaction. Additionally, 88.2% of patients agreed that the scribe enabled the physician to pay more attention to them, and 90.1% (75.5% strongly agreed and 14.6% agreed) felt that their physician was more focused during the visit.
Operational efficiency was positively perceived, with 90.9% (72.7% strongly agreed; 18.2% agreed) indicating that the AI scribe made the consultation more efficient than before.
Confidence in data privacy was also high: 87.2% of respondents felt either “very confident” or “confident” regarding the confidentiality of their information.
Importantly, 61.8% of the respondents reported that the presence of the AI scribe increased their willingness to share personal health information.
Overall satisfaction was high, with 79.1% being “very satisfied” and 13.6% “satisfied” respectively.
Reflecting this positive experience, 95.5% of the respondents stated that they would either "definitely" or "probably" recommend the technology for future consultations.
These findings highlight that effective physician communication and careful implementation contribute to the successful integration of AI scribes in a sensitive oncological setting.
Notably, the high levels of comfort and perceived enhancement of physician attentiveness suggest that the technology was seen as facilitating—rather than hindering—the human element of care.
Our evaluation of the AI-powered medical scribe in an oncological outpatient setting demonstrated rapid AI draft generation and high note quality, alongside high physician satisfaction and positive patient experience.
Importantly, our evaluation focused on documentation components (AI draft generation time and perceived efficiency) rather than the total end-to-end clinician documentation time or the full visit workflow (e.g., EHR integration, encounter closure). These findings are consistent with the emerging literature on AI-assisted documentation while providing evidence from a high-stakes oncology environment.
In our study, physicians were able to complete notes faster and spend less time on clerical tasks, mirroring the time savings reported with human virtual assistants. For example, Rotenstein et al. found that using virtual medical scribes reduced the total EHR time per appointment by an average of 5.6 minutes, as well as decreased in-clinic note-writing time and after-hours “pajama time”.11
In our oncology clinic, the AI scribe’s ambient documentation similarly freed physicians from the keyboard, allowing them to focus more on direct patient care. This efficiency gain is particularly impactful in oncology, where visits often involve complex discussions and care coordination issues.
Our results align with those of Langdon et al.12, who reported that implementing Speaknosis in a pediatric ENT practice enabled clinicians to spend “only a fraction of the time” reviewing and editing documentation compared with manual entry. Taken together, these data confirm that AI-driven scribes can meaningfully lighten the documentation workload in both general and specialty care settings, potentially mitigating burnout and improving the workflow.
Equally important, the quality of the documentation produced by the AI scribe in our study remained high. Oncology outpatient notes are rich in detail, including diagnoses, staging information, treatment plans, and follow-up instructions; therefore, maintaining accuracy and completeness is critical.
We found that Speaknosis-generated notes were comprehensive and well-organized, with only minor edits needed for correctness. This is in line with the high documentation quality observed by Langdon et al.12 in ENT clinics, where Speaknosis notes achieved a mean PDQI-9 score of ~38 (out of 45), indicating a good overall quality. In that study, the AI drafts were strong in terms of organization and consistency, although human intervention was occasionally required to address omitted findings or formatting issues.
Our oncology implementation similarly required clinician oversight to identify infrequent omissions or clarify ambiguous content, underscoring the fact that human review remains essential for safety.
Notably, the degree of AI assistance in our study did not compromise note quality relative to traditional documentation; if anything, note consistency and structure improved owing to the AI’s templating and summarization capabilities. This contrasts with recent studies that used a general-purpose large language model without domain tuning.
Kernberg et al.13 evaluated ChatGPT-4 on generating SOAP notes and found an average of 23.6 errors per case, with the vast majority (≈86%) being omissions of important details. They concluded that the standalone GPT-4 notes were too unreliable for clinical use, given the substantial variability and information gaps.
In our study, by leveraging a specialized scribe system and real-time physician oversight, no critical errors were identified during clinician review prior to note finalization; however, we did not conduct a formal, independently adjudicated severity grading, so these observations should be interpreted cautiously.
This interpretation is bolstered by the comparative findings of Lee et al.14, who showed that a fine-tuned clinical documentation model outperformed a general GPT-based model in terms of recall, precision, and overall note fidelity. The specialized scribe not only captured more relevant clinical content but also produced notes with fewer hallucinations and higher clinician-rated comprehensiveness and usefulness than the standard LLM.
Our results echo this advantage of domain-trained AI: in the complex oncological setting, the Speaknosis system reliably captured nuanced patient information (e.g., cancer histories, treatment responses, side effects) with minimal false additions, whereas a generic model might miss subtleties or introduce inaccuracies. This high degree of accuracy in cancer care is a noteworthy advancement, as it demonstrates that AI documentation tools can be trusted in environments where errors have serious consequences.
Another key finding of our study was the positive reception by the clinicians. Physician satisfaction with the AI scribe was high, which we attribute to the reduced administrative burden and improved note quality.
Oncologists in our trial reported that the system streamlined their workflow, allowing them to complete notes more quickly without sacrificing thoroughness. This sentiment aligns with the experience of ENT clinicians in Langdon et al.’s12 Speaknosis study, where satisfaction averaged 4.6/5.
In that study, higher satisfaction was correlated with better documentation quality and efficiency gains, a trend we likewise observed; physicians were most pleased with the AI scribe during encounters where the generated note needed minimal editing, and the visit flowed uninterrupted.
Notably, our study suggests that integrating an AI scribe can improve the physician-patient interaction by reducing “screen time.”
Many oncologists struggle to balance computer documentation and empathetic patient communication, as oncology visits often involve delivering serious news or complex care planning. With Speaknosis handling the transcription in the background, clinicians in our study maintained more eye contact and engaged in active listening, which they felt improved their clinical encounters.
From the patient’s perspective, this translated into a better experience: patients did not feel neglected by note-taking, and in some cases, commented that the visit seemed more personal and focused.
Although patient satisfaction scores in our pilot did not show a statistically significant increase (likely due to an already high baseline in our center), there was no decline in patient-reported experience, indicating that the AI scribe did not disrupt care. This addresses the common concern that technology could interfere with the human touch in medicine.
Emerging evidence suggests that AI-assisted notes may enhance the patient-centeredness of documentation. Kharko et al.15 recently explored the use of GPT-3.5/4.0 to draft patient-facing “open notes” and found that the AI-generated notes exhibited greater expressions of empathy and supportive language, although sometimes at the expense of medical detail.
Our study was not designed to explicitly measure empathy in documentation, but it is reassuring that delegating note-taking to an AI did not detract from the compassionate communication that is vital in oncology care.
If anything, freeing clinicians from typing may allow them to devote more attention to empathetic dialogue while still producing complete and accurate notes for the record. This highlights an important way in which our work advances the field: it not only confirms technical feasibility and efficiency in a critical care domain but also suggests that AI scribes can be introduced without eroding, and potentially while enhancing, the quality of doctor-patient interactions in emotionally charged clinical contexts.
Study Limitations
Despite its promising results, this study has several limitations.
- Analytical vs. clinical validation. While BERTScore/CBERTScore provide evidence of semantic similarity between drafts and finalized notes, these metrics represent an analytical, text-based validation rather than an end-to-end clinical, functional, or institutional validation of the system. Additional evaluations (e.g., workflow integration testing, failure-mode analysis, and risk assessment under intended use) are warranted.
- Critical errors and patient safety. We did not prospectively define and quantify “critical errors” using an independent adjudication panel. For clarity, we consider critical errors as omissions or commissions that could plausibly lead to patient harm if left uncorrected (e.g., allergies, active medications, major diagnoses, contraindications, or treatment plan details). Although clinicians reviewed and corrected all notes prior to finalization, future work should include a structured taxonomy (omissions vs. commissions) and severity grading with frequency reporting.
- Dependence on external foundation models. System performance in this study depended on specific versions of external foundation models (Gemini Flash 2.0 for report generation and Gemini Flash 1.5 for transcription). Because model updates can change behavior and risk profiles, our results should be interpreted as a time-specific snapshot of system performance under these versions.
- Ongoing monitoring and revalidation. We did not evaluate long-term model drift, monitoring strategies, or periodic revalidation after software or model updates. Given the dynamic nature of AI systems, future deployments should incorporate continuous quality monitoring, predefined performance thresholds, and scheduled revalidation in real-world use.
- Language and cultural context. We did not explicitly test performance under regionalisms, colloquial expressions, or culturally specific narratives in Spanish. As language models may normalize patient speech, this may introduce risks of omission or reinterpretation; dedicated evaluation in diverse Spanish-language contexts is needed.
- Pediatric generalizability. Pediatric encounters were essentially absent in our sample; thus, the findings should not be generalized to pediatric populations without dedicated evaluation.
- Cybersecurity and institutional governance. Although we address privacy and data protection, we did not formally assess institutional cybersecurity considerations associated with integrating an external AI vendor into clinical environments (e.g., identity and access management, encryption at rest/in transit, audit logs, incident response, and vendor risk management). These aspects are essential for scalable deployment and should be addressed in future implementations.
- Future model evolution. Any migration to newer or more advanced language models should be considered conditional; each new model/version would require independent evaluation and revalidation, and our current results should not be extrapolated to future system versions without such testing.
Future Directions and Implications
Our findings pave the way for several practical steps. A top priority is the deeper integration of AI scribes into EHR systems. Currently, our deployment requires physicians to review AI-generated text and manually import it into the EHR. Closer integration - for example, having the AI directly populate structured fields or insert notes into the EHR with appropriate formatting - could further streamline the workflow.
Such integration should be pursued in collaboration with EHR vendors while maintaining transparency so that clinicians always know which parts of the note are AI-generated.
In parallel, any EHR integration should be accompanied by institutional cybersecurity and governance controls (e.g., access management, encryption, audit logging, vendor risk management, and incident response procedures). Moreover, since system behavior may change after software or model updates, integration roadmaps should include predefined monitoring and periodic revalidation to ensure sustained performance and safety.
Another important future direction is to examine longitudinal patient outcomes and care quality metrics. It would be valuable to assess whether alleviating physicians’ documentation burden translates into measurable improvements in care. For instance:
- Does it increase the time spent on patient education or care coordination, potentially improving treatment adherence or patient understanding of their cancer care plans?
- Do error rates in documentation (such as missed allergies or incorrect medications) decrease in the long term with AI assistance, thereby enhancing patient safety?
These questions require longer studies that track patients and providers over time and compare outcomes before and after AI scribe implementation.
Additionally, expansion to other clinical settings will be required to test the generalizability of our results. While our study demonstrates success in an outpatient oncology clinic, future research should explore AI scribes in inpatient oncology (where multidisciplinary teams and longer narrative notes are common) and other high-complexity fields, such as cardiology or critical care.
Each setting may present unique challenges; for example, intensive care notes involve continuous data streams, and surgical oncology notes may require integrating operative reports; therefore, iterative refinement of the AI will be necessary.
We also recommend exploring multilingual capabilities, since oncology care often spans diverse populations; an AI scribe that can function in the local language (Spanish, in our case) and produce notes in the preferred language of the medical record is highly valuable for this purpose.
Moreover, as these tools become more widespread, it is crucial to establish the best practices for their responsible deployment.
Our experience reinforces recent calls for rigorous oversight and governance of clinical AI systems. This includes implementing robust safety checks, real-time error monitoring, and fallback procedures in case of AI failure, as well as training clinicians on how to use and audit the AI’s contributions effectively.
Developing standard guidelines, akin to those proposed by Labkoff et al.16 for AI-based clinical decision support, will help ensure that ambient scribe technologies improve care delivery without introducing new risks to patients.
Finally, continued collaboration among front-line clinicians, medical informaticians, and AI developers will be key to refining the performance of scribes.
Feedback from oncologists in our study has already highlighted areas for improvement, such as better recognition of medical acronyms and more concise summarization of follow-up plans. Incorporating such feedback into future model updates and, possibly, leveraging more advanced large language models as they become available could further enhance the system's accuracy and utility.
In summary, this study provides encouraging evidence that an AI medical scribe can be safely and effectively employed in high-stakes oncology outpatient settings. It not only eases the documentation workload and produces quality notes comparable to traditional methods but also preserves the humanistic aspects of patient care.
By demonstrating feasibility in one of the most information-intensive and emotionally delicate domains of medicine, our study advances the field of clinical AI.
Ongoing research and responsible innovation will determine how far such tools can go in transforming healthcare documentation, ultimately striving for the dual goals of improving provider well-being and optimizing patient care.
Our study demonstrates that an AI-powered medical scribe can enhance documentation efficiency, maintain high-quality notes, and support physician satisfaction in a complex oncology outpatient setting.
By reducing administrative burden without compromising clinical accuracy or patient experience, specialized AI tools like Speaknosis represent a promising step toward more human-centered, efficient healthcare workflows. Continued refinement, integration, and evaluation across diverse clinical environments will be key to unlocking their full potential.
The first author is a board member of the company that developed the software evaluated in this study and holds 30% equity in the company. However, no financial compensation has been received, as the product has not yet been commercialized. To mitigate potential bias, the first author did not participate in patient visits, clinical encounters, or data collection and performed the data analysis in a blinded manner.
This potential conflict of interest was fully disclosed and reviewed by the Ethics Committee of the Instituto Oncológico Fundación Arturo López Pérez (FALP), which approved the study protocol.
All participating physicians were informed of this relationship during the consent process.
Disclosure to patients was not required by the ethics committee.
The study was conducted in accordance with institutional and ethical standards to ensure transparency, objectivity, and scientific integrity.
| 1. | Shanafelt TD, Dyrbye LN, Sinsky C, Hasan O, Satele D, Sloan J, et al. Relationship between clerical burden and characteristics of the electronic environment with physician burnout and professional satisfaction. Mayo Clin Proc. 2016;91(7):836-48. |
| 2. | Asgari E, Kaur J, Nuredini G, Balloch J, Taylor AM, Sebire N, et al. Impact of electronic health record use on cognitive load and burnout among clinicians: Narrative review. JMIR Med Inform. 2024;12:e55499. |
| 3. | Office of the National Coordinator for Health Information Technology. Strategy on reducing burden relating to the use of health IT and EHRs. Washington, DC: U.S. Department of Health and Human Services; 2020. [Retrieved on March 2nd, 2026]. Available from URL: https://healthit.gov/wp-content/uploads/2020/02/BurdenReport.pdf |
| 4. | Guo Y, Hu D, Wang J, Zheng K, Perret D, Pandita D, et al. Ambient listening in clinical practice: Evaluating EPIC signal data before and after implementation and its impact on physician workload. Stud Health Technol Inform. 2025;329:653-657. |
| 5. | Palm E, Manikantan A, Mahal H, Belwadi SS, Pepin ME. Assessing the quality of AI-generated clinical notes: A validated evaluation of a large language model scribe. Front Artf Intell. 2505;8:1691499. |
| 6. | Khairat S, Burke G, Archambault H, Schwartz T, Larson J, Ratwani RM. Perceived burden of EHRs on physicians at different stages of their career. Appl Clin Inform. 2018;9(3):336-347. |
| 7. | Gellert GA, Ramirez R, Webster SL. The rise of the medical scribe industry: Implications for the advancement of electronic health records. JAMA. 2015;313(13):1315-6. |
| 8. | Wang Y, Liu S, Afzal N, Rastegar-Mojarad M, Wang L, Shen F, et al. A comparison of word embeddings for the biomedical natural language processing. J Biomed Inform. 2018;87:12-20. |
| 9. | Rajkomar A, Hardt M, Howell MD, Corrado G, Chin MH. Ensuring fairness in machine learning to advance health equity. Ann Intern Med. 2018;169(12):866-72. |
| 10. | Spinazze P, Aardoom J, Chavannes N, Kasteleyn M. The computer will see you now: Overcoming barriers to adoption of computer-assisted history taking (CAHT) in primary care. J Med Internet Res. 2021;23(2):e19306. |
| 11. | Rotenstein L, Melnick ER, Iannaccone C, Zhang J, Mugal A, Lipsitz SR, et al. Virtual scribes and physician time spent on electronic health records. JAMA Netw Open. 2024;7(5):e2413140. |
| 12. | Langdon C, Haag O, Vigliano M, Levorato M, Leon-Ulate J, Adroher M. Transforming pediatric ENT documentation: Efficiency, accuracy, and adoption of speech recognition technology (Speaknosis). Int J Pediatr Otorhinolaryngol. 2025;191:112275. |
| 13. | Kernberg A, Gold JA, Mohan V. Using ChatGPT-4 to create structured medical notes from audio recordings of physician-patient encounters: Comparative study. J Med Internet Res. 2024;26:e54419. |
| 14. | Lee C, Kumar S, Vogt KA, Meraj S. Ambient AI scribing support: Comparing the performance of specialized AI agentic architecture to leading foundational models. Sporo Health; 2024. [Retrieved on March 3rd, 2026]. Available from URL: https://arxiv.org/pdf/2411.06713 |
| 15. | Kharko A, McMillan B, Hagström J, Muli I, Davidge G, Hägglund M, et al. Generative artificial intelligence writing open notes: A mixed methods assessment of the functionality of GPT 3.5 and GPT 4.0. Digit Health. 2024;10:20552076241291384. |
| 16. | Labkoff S, Oladimeji B, Kannry J, Solomonides A, Leftwich R, Koski E, et al. Toward a responsible future: Recommendations for AI-enabled clinical decision support. J Am Med Inform Assoc. 2024;31(11):2730-2739. |
All Rights Reserved® 2019
Latin American Journal of Clinical Sciences and Medical Technology,Publicación contínua • Editor responsable: Gilberto Castañeda Hernández. • Reserva de Derechos al Uso Exclusivo: 04-2019-062013242000-203; ISSN: 2683-2291; ambos otorgados por el Instituto Nacional del Derecho de Autor. • Responsable de la última actualización de este número, Web Master Hunahpú Velázquez Martínez,
Calle Profesor Miguel Serrano #8, Col. Del Valle, Alcaldía Benito Juárez, CP 03100, Ciudad de México, México. Número telefónico: 55 5405 1396 • Fecha de última modificación, 28 de agosto de 2024.
All Rights Reserved® 2019
Publicación contínua • Editor responsable: Gilberto Castañeda Hernández. • Reserva de Derechos al Uso Exclusivo: 04-2019-062013242000-203; ISSN: 2683-2291; ambos otorgados por el Instituto Nacional del Derecho de Autor. • Responsable de la última actualización de este número, Web Master Hunahpú Velázquez Martínez,
Calle Profesor Miguel Serrano #8, Col. Del Valle, Alcaldía Benito Juárez, CP 03100, Ciudad de México, México. Número telefónico: 55 5405 1396 • Fecha de última modificación, 28 de agosto de 2024.